
zookeeperr(分布式应用程序协调服务)
详情介绍
zookeeper是一个开源的分布式应用程序协调服务,是Google的chubby一个开源的实现,是Hadoop和Hbase的重要组成部件。除了能够为用户的分布式应用提供一致性的服务,还能够进行配置维护、域名服务、分布式同步等等功能,对于开发人员来说,这款软件是一个非常高效可靠的服务软件。zookeeper的目标是为了封装好复杂易出错的关键服务,将简单易用的借口和性能高效、功能稳定的系统提供给用户,软件拥有两个接口,Java和C语言,也就是说目前还是只有这两个开发语言的用户使用的较多。
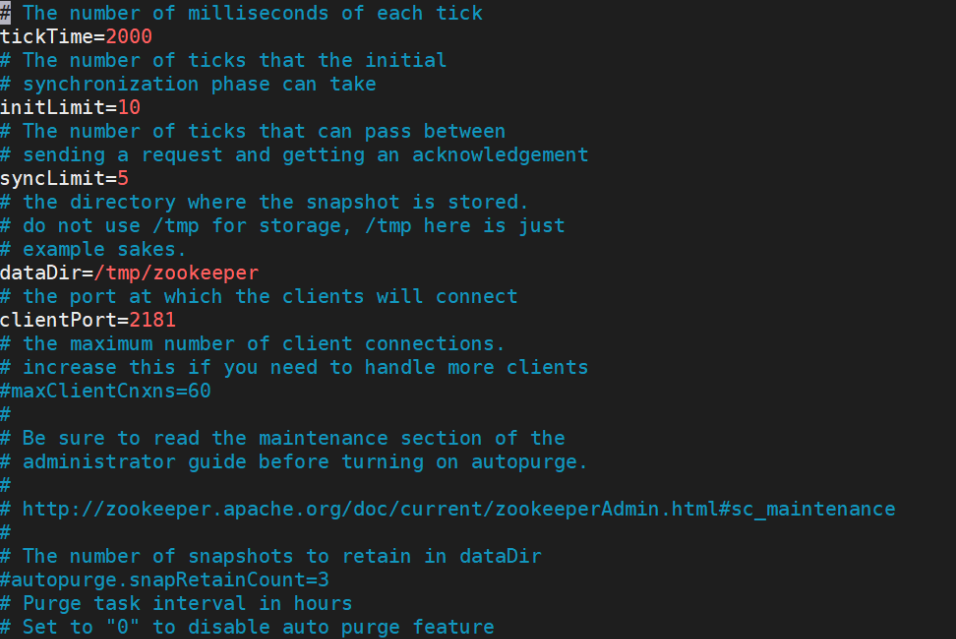
如下图所示:
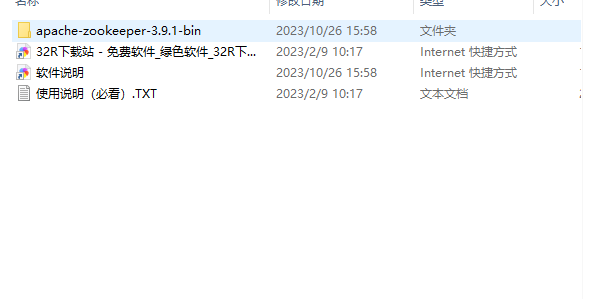
2、解压后进入conf文件夹下面,把zoo_sample.cfg复制一份并改名为zoo.cfg。
如下图所示:
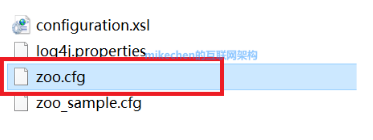
备注:zoo.cfg是zookeeper配置文件入口,必须修改为zoo.cfg.
3、在根目录下新建一个data文件夹和一个log文件夹,分别存储数据和日志。

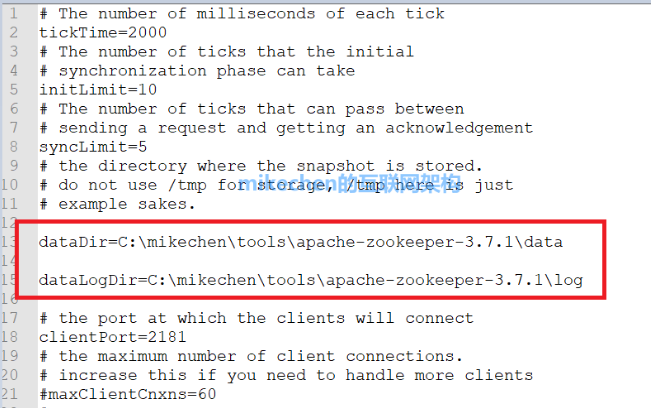
4、进入conf文件夹下面,修改zoo.cfg配置文件,把dataDir=/tmp/zookeeper修改成zookeeper安装目录所在的data文件夹,以及dataLogDir修改为log文件夹。
如下图所示:
进入bin文件夹,双击点击zkServer.cmd启动zookeeper。
如下图所示:
控制台显示:

启动zookeeper客户端
双击zkCli.cmd启动客户端,出现:

表示启动成功了。
2、同步数据。
3、选举Leader过程中算法有很多,但要达到的选举标准是一致的。
4、Leader要具有最高的zxid。
5、集群中大多数的机器得到响应并follow选出的Leader。
那么Zookeeper能做什么事情呢,简单的例子:假设我们有20个搜索引擎的服务器(每个负责总索引中的一部分的搜索任务)和一个总服务器(负责向这20个搜索引擎的服务器发出搜索请求并合并结果集),一个备用的总服务器(负责当总服务器宕机时替换总服务器),一个web的cgi(向总服务器发出搜索请求)。搜索引擎的服务器中的15个服务器提供搜索服务,5个服务器正在生成索引。这20个搜索引擎的服务器经常要让正在提供搜索服务的服务器停止提供服务开始生成索引,或生成索引的服务器已经把索引生成完成可以提供搜索服务了。使用Zookeeper可以保证总服务器自动感知有多少提供搜索引擎的服务器并向这些服务器发出搜索请求,当总服务器宕机时自动启用备用的总服务器。

zookeeper安装
1、下载完最新zookeeper 3.9.1稳定版本后,解压下载的压缩包。如下图所示:

2、解压后进入conf文件夹下面,把zoo_sample.cfg复制一份并改名为zoo.cfg。
如下图所示:

备注:zoo.cfg是zookeeper配置文件入口,必须修改为zoo.cfg.
3、在根目录下新建一个data文件夹和一个log文件夹,分别存储数据和日志。

4、进入conf文件夹下面,修改zoo.cfg配置文件,把dataDir=/tmp/zookeeper修改成zookeeper安装目录所在的data文件夹,以及dataLogDir修改为log文件夹。
如下图所示:

zookeeper启动流程
启动zookeeper服务端进入bin文件夹,双击点击zkServer.cmd启动zookeeper。
如下图所示:

控制台显示:

启动zookeeper客户端
双击zkCli.cmd启动客户端,出现:

表示启动成功了。
zookeeper原理
1、选举Leader。2、同步数据。
3、选举Leader过程中算法有很多,但要达到的选举标准是一致的。
4、Leader要具有最高的zxid。
5、集群中大多数的机器得到响应并follow选出的Leader。
软件特点
在Zookeeper中,znode是一个跟Unix文件系统路径相似的节点,可以往这个节点存储或获取数据。如果在创建znode时Flag设置为EPHEMERAL,那么当创建这个znode的节点和Zookeeper失去连接后,这个znode将不再存在在Zookeeper里,Zookeeper使用Watcher察觉事件信息。当客户端接收到事件信息,比如连接超时、节点数据改变、子节点改变,可以调用相应的行为来处理数据。Zookeeper的Wiki页面展示了如何使用Zookeeper来处理事件通知,队列,优先队列,锁,共享锁,可撤销的共享锁,两阶段提交。那么Zookeeper能做什么事情呢,简单的例子:假设我们有20个搜索引擎的服务器(每个负责总索引中的一部分的搜索任务)和一个总服务器(负责向这20个搜索引擎的服务器发出搜索请求并合并结果集),一个备用的总服务器(负责当总服务器宕机时替换总服务器),一个web的cgi(向总服务器发出搜索请求)。搜索引擎的服务器中的15个服务器提供搜索服务,5个服务器正在生成索引。这20个搜索引擎的服务器经常要让正在提供搜索服务的服务器停止提供服务开始生成索引,或生成索引的服务器已经把索引生成完成可以提供搜索服务了。使用Zookeeper可以保证总服务器自动感知有多少提供搜索引擎的服务器并向这些服务器发出搜索请求,当总服务器宕机时自动启用备用的总服务器。
同类软件
网友评论
共0条评论(您的评论需要经过审核才能显示)
 赣公网安备 36010602000087号
赣公网安备 36010602000087号