
八爪鱼采集器官方版(免费网络爬虫软件)
详情介绍
信息碎片化时代,互联网上每天都有数以万计的新信息发布,为了抢夺大众的注意力,占用他们的碎片化时间,各大网站或app的招数也是层出不穷。许多新闻平台都有兴趣推荐机制,拥有成熟先进的内容推荐算法,可以捕捉用户的兴趣标签,将用户感兴趣的内容推送到他的首页。虽然拥有先进的内容推荐算法与互联网用户画像数据,但仍然缺乏海量的内容:比如做内容分发的,他们需要将各个新闻资讯平台更新的数据实时采集下来,再通过个性化推荐系统将其分发给感兴趣的人;做垂直内容聚合的,需要搜集互联网上某特定领域、特定分类下的新闻资讯数据,再发布到自己的平台上。八爪鱼采集器一款通用的网页数据采集软件。可以对上百种主流网站数据源进行模板采集,不但节省时间还可以快速获取网站公开数据,软件可以根据不同网站智能采集并提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。支持字符串替换、还具备采集Cookie自定义功能,首次登录以后,可以自动记住cookie,免去多次输入密码的繁琐,感兴趣的小伙伴快来下载体验一下吧!
简易采集模式内置上百种主流网站数据源,如京东、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
2、智能采集
八爪鱼采集可根据不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
3、云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提升采集效率,保障数据时效性。
4、API接口
通过八爪鱼API,可以轻松获取八爪鱼任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强大的API体系,还可以无缝对接公司内部各类管理平台,实现各类业务自动化。
5、自定义采集
针对不同用户的采集需求,八爪鱼可提供自动生成爬虫的自定义模式,可准确批量识别各种网页元素,还有翻页、下拉、ajax、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
6、便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某一天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据需要对选择时间进行多重组合,灵活调配自己的采集任务。
7、全自动数据格式化
八爪鱼内置了强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集过程中全自动处理,无需人工干预,即可得到所需格式数据。
8、多层级采集
很多主流新闻、电商类的网站,里面包含一级商品列表页,也包含二级商品详情页,还有三级评论详情页面;不论网站有多少层级,八爪鱼都可以不限制层级的采集数据,满足各类业务采集需求。
9、支持网站登录后采集
八爪鱼内置了采集登录模块,只需配置目标网站的账号密码,即可用该模块采集到登录后的数据;同时八爪鱼还具备采集Cookie自定义功能,首次登录以后,可以自动记住cookie,免去多次输入密码的繁琐,支持更多网站的采集。
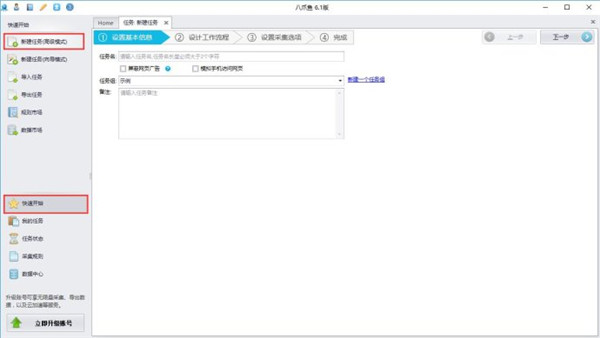
2、选择任务组,自定义任务名称和备注;
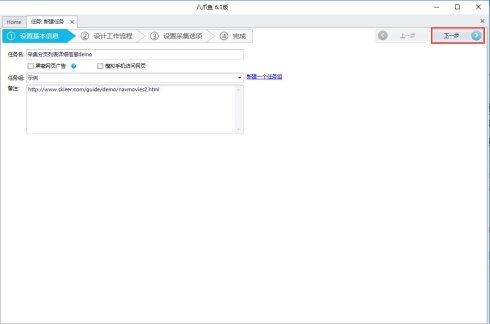
3、上图配置完毕之后,选择下一步,进入到流程配置页面,往流程设计中拖入一个打开网页的步骤。
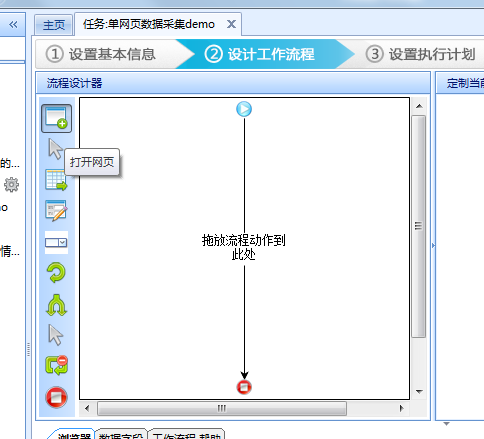
4、选中浏览器中的打开网页步骤,在右边的页面URL中输入网页URL并点击保存,系统会在软件下方的浏览器中自动打开对应网页:
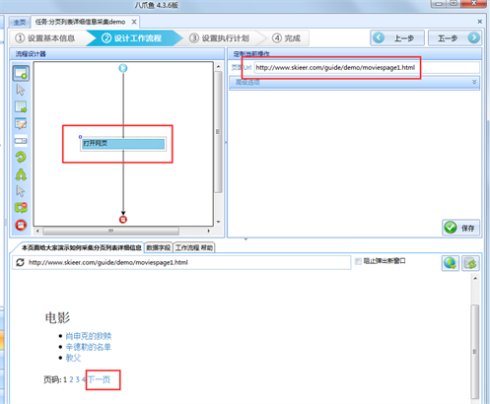
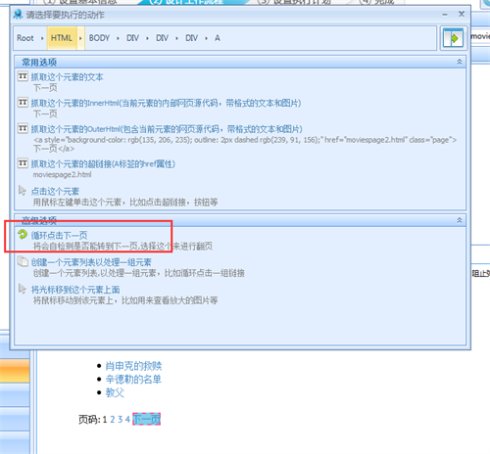
5、下面创建循环翻页。点击上图浏览器页面中的下一页按钮,在弹出的对话框中选择循环点击下一页;
6、翻页循环创建完毕之后,点击下图中的保存;
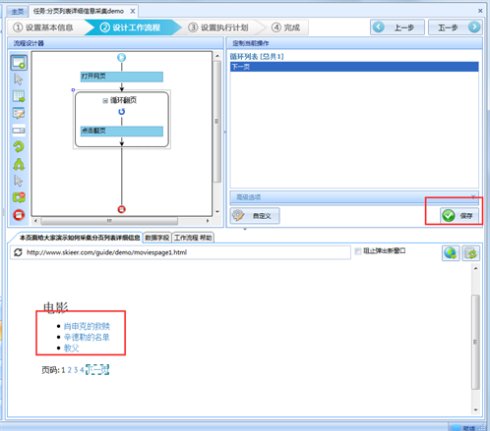
7、由于我们需要循环点击上图浏览器中电影名称,再提取子页面中的数据信息,所以我们需要做一个循环采集列表。
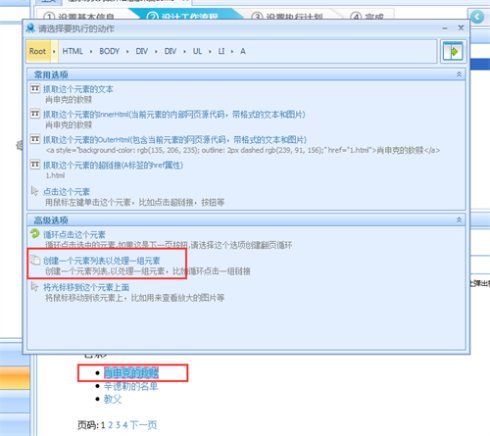
点击上图中第一个循环项,在弹出的对话框中选择创建一个元素列表以处理一组元素;
8、接下来在弹出的对话框中选择添加到列表。
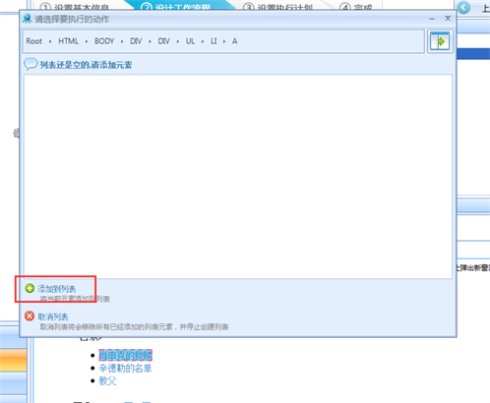
9、第一个循环添加好之后继续编辑。
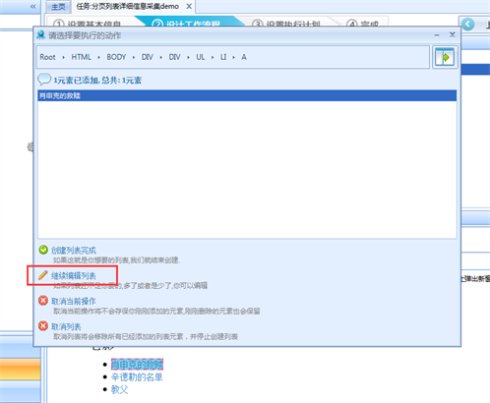
10、接下来以同样的方式添加第二个循环。
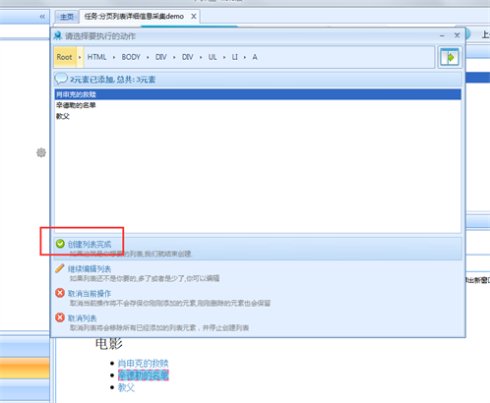
11、我们添加第二个循环项的时候可以看上图,这时候页面中其他元素都被添加进来了。这是因为我们添加的是具有两个相似特征的元素,系统会智能的将页面中其他具有相似特征的元素都添加进来。然后选择创建列表完成→点击下图中的循环。
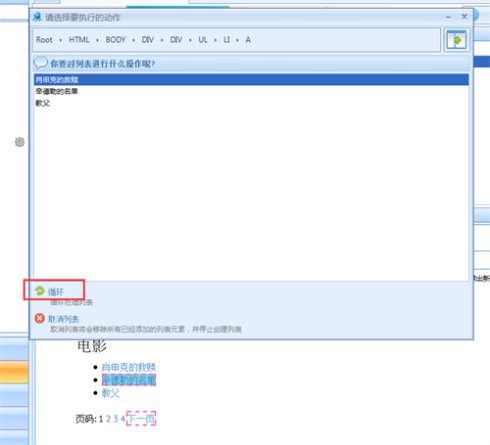
12、如上操作之后,循环采集列表就完成了。系统会在页面右上方显示本页面添加进来的所有循环项。
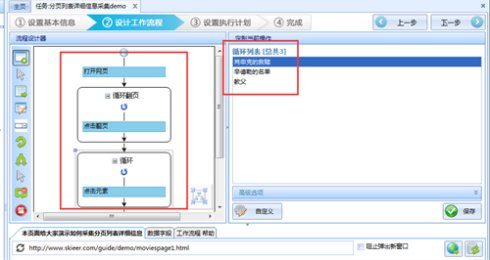
13、由于每一页都需要循环采集数据,所以我们需要将这个循环列表拖入到翻页循环里。
注意流程是从上网页执行的,所以这个循环列表需要放到点击翻页的前面,否则会漏掉第一页的数据。最终流程图如下图所示:
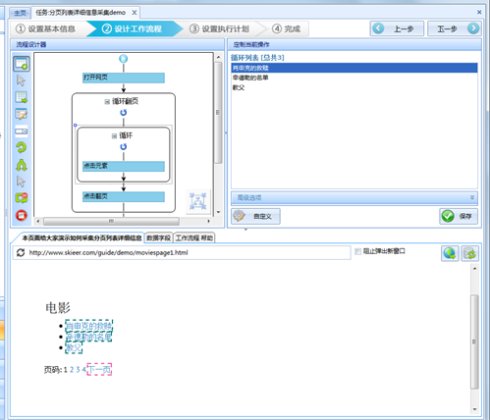
14、选择上图中第一个循环项,再选择点击元素.进入到第一个子链接里面。
下面进行数据字段的提取,点击上图流程设计器中的提取数据,再选择浏览器中需要提取的字段,然后在弹出的选择对话框中选择抓取这个元素的文本;
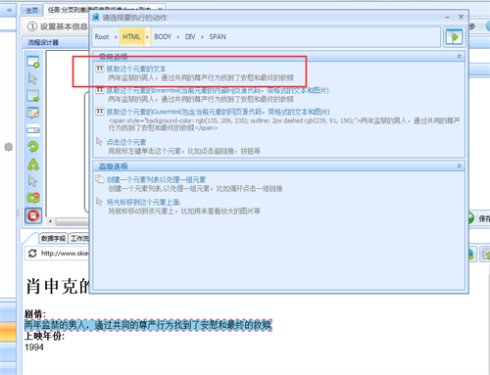
15、上述操作之后,系统会在页面的右上方显示我们将要抓取的字段;
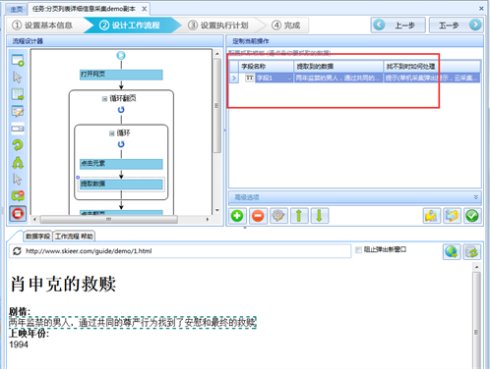
16、接下来配置页面中其他需要抓取的字段,配置完成之后修改字段名称。
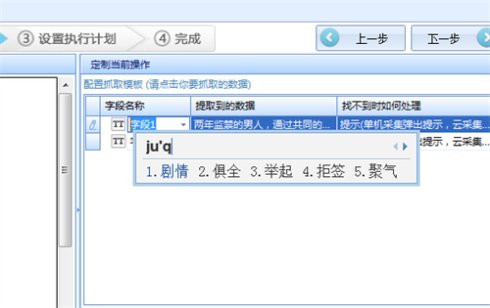
17、修改完成之后点击上图中的保存按钮,再点开图中的数据字段可以看到,系统将会显示最终的采集列表。
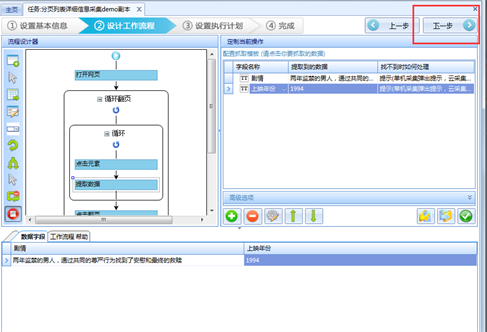
18、点击上图中的下一步→下一步→启动单机采集,进入到任务检查页面,以确保任务的正确性。
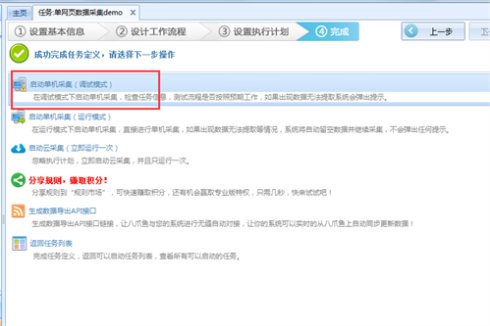
19、点击开始单机采集,系统将会在本地执行采集流程并显示最终采集的结果。
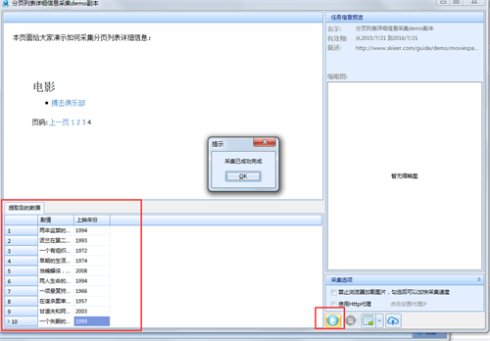
适合产品、运营、销售、数据分析、政府机关、电商从业者、学术研究等多种身份职业
2、舆情监控
全方位监测公开信息,抢先获取舆论趋势
3、市场分析
获取用户真实行为数据,全面把握顾客真实需求
4、产品研发
强力支撑用户调研,准确获取用户反馈和偏好
5、风险预测
高效信息采集和数据清洗,及时应对系统风险

八爪鱼采集器功能介绍
1、简易采集简易采集模式内置上百种主流网站数据源,如京东、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
2、智能采集
八爪鱼采集可根据不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
3、云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提升采集效率,保障数据时效性。
4、API接口
通过八爪鱼API,可以轻松获取八爪鱼任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强大的API体系,还可以无缝对接公司内部各类管理平台,实现各类业务自动化。
5、自定义采集
针对不同用户的采集需求,八爪鱼可提供自动生成爬虫的自定义模式,可准确批量识别各种网页元素,还有翻页、下拉、ajax、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
6、便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某一天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据需要对选择时间进行多重组合,灵活调配自己的采集任务。
7、全自动数据格式化
八爪鱼内置了强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集过程中全自动处理,无需人工干预,即可得到所需格式数据。
8、多层级采集
很多主流新闻、电商类的网站,里面包含一级商品列表页,也包含二级商品详情页,还有三级评论详情页面;不论网站有多少层级,八爪鱼都可以不限制层级的采集数据,满足各类业务采集需求。
9、支持网站登录后采集
八爪鱼内置了采集登录模块,只需配置目标网站的账号密码,即可用该模块采集到登录后的数据;同时八爪鱼还具备采集Cookie自定义功能,首次登录以后,可以自动记住cookie,免去多次输入密码的繁琐,支持更多网站的采集。
八爪鱼采集器使用教程
1、首先打开八爪鱼采集器→点击快速开始→新建任务(高级模式),进入到任务配置页面:
2、选择任务组,自定义任务名称和备注;

3、上图配置完毕之后,选择下一步,进入到流程配置页面,往流程设计中拖入一个打开网页的步骤。

4、选中浏览器中的打开网页步骤,在右边的页面URL中输入网页URL并点击保存,系统会在软件下方的浏览器中自动打开对应网页:

5、下面创建循环翻页。点击上图浏览器页面中的下一页按钮,在弹出的对话框中选择循环点击下一页;

6、翻页循环创建完毕之后,点击下图中的保存;

7、由于我们需要循环点击上图浏览器中电影名称,再提取子页面中的数据信息,所以我们需要做一个循环采集列表。

点击上图中第一个循环项,在弹出的对话框中选择创建一个元素列表以处理一组元素;
8、接下来在弹出的对话框中选择添加到列表。

9、第一个循环添加好之后继续编辑。

10、接下来以同样的方式添加第二个循环。

11、我们添加第二个循环项的时候可以看上图,这时候页面中其他元素都被添加进来了。这是因为我们添加的是具有两个相似特征的元素,系统会智能的将页面中其他具有相似特征的元素都添加进来。然后选择创建列表完成→点击下图中的循环。

12、如上操作之后,循环采集列表就完成了。系统会在页面右上方显示本页面添加进来的所有循环项。

13、由于每一页都需要循环采集数据,所以我们需要将这个循环列表拖入到翻页循环里。
注意流程是从上网页执行的,所以这个循环列表需要放到点击翻页的前面,否则会漏掉第一页的数据。最终流程图如下图所示:

14、选择上图中第一个循环项,再选择点击元素.进入到第一个子链接里面。
下面进行数据字段的提取,点击上图流程设计器中的提取数据,再选择浏览器中需要提取的字段,然后在弹出的选择对话框中选择抓取这个元素的文本;

15、上述操作之后,系统会在页面的右上方显示我们将要抓取的字段;

16、接下来配置页面中其他需要抓取的字段,配置完成之后修改字段名称。

17、修改完成之后点击上图中的保存按钮,再点开图中的数据字段可以看到,系统将会显示最终的采集列表。

18、点击上图中的下一步→下一步→启动单机采集,进入到任务检查页面,以确保任务的正确性。

19、点击开始单机采集,系统将会在本地执行采集流程并显示最终采集的结果。

软件优势
1、满足多种业务场景适合产品、运营、销售、数据分析、政府机关、电商从业者、学术研究等多种身份职业
2、舆情监控
全方位监测公开信息,抢先获取舆论趋势
3、市场分析
获取用户真实行为数据,全面把握顾客真实需求
4、产品研发
强力支撑用户调研,准确获取用户反馈和偏好
5、风险预测
高效信息采集和数据清洗,及时应对系统风险
猜您喜欢
- 电脑数据采集软件
- 工作中大家可能会用到一些数据,而苦于没有好的数据采集软件,只能一个一个的去网站采集。数据采集,又称数据获取,是利用一种装置,从系统外部采集数据并输入到系统内部的一个接口。数据采集技术目前广泛应用于各个领域。针对制造业企业的庞大生产数据,数据采集工具尤为重要。那么市场上数据采集工具有哪些?3322小编整理了一批好用的数据采集软件,安装后可以轻松的采集到你想要的数据,还不赶快下载安装。
-

EditorTools2(全自动采集器) v2.7官方版 网站优化 / 8.7M
-

火车头采集器官方版 v10.24正式版 网络辅助 / 53.96M
-

爬山虎采集器官方版 v3.1.0.0 网络辅助 / 61.81M
-

后羿采集器 v4.0.2官方版 网络辅助 / 81.78M
-

懒人采集器(网页资源采集工具)官方版 v3.2.9.1 网络辅助 / 85.66M
-

八爪鱼采集器官方版(免费网络爬虫软件) v8.6.7 网络辅助 / 79.69M
同类软件
网友评论
共0条评论(您的评论需要经过审核才能显示)

 赣公网安备 36010602000087号
赣公网安备 36010602000087号